
Semgrep 👀
A Swiss Army knife for understanding code

👋 Hello hello!
I know, it’s been around a month since my last post. I’ve received a few queries, including one from my own mother, asking where the newsletter has gone. Have I gone off it already?
Fear not. I’ve been off on holiday celebrating a big birthday, and wanted to take a total break from work and writing. I didn’t want to spam your inboxes sending an additional issue just to tell you this. Now, I’m back, re-energised, and ready to go. ☺️
If this is your first time here, hello! I’ve spent the past 7 years working for high growth companies. My path has followed a ‘do-what-needs-to-be-done’ path: software engineering, data science, machine learning, with a little product management thrown in for good measure. I’ve picked up some useful experience at the intersection of these disciplines, and I’d love to share it with you.
The goal of this newsletter is to discuss techniques for building better software and being more effective in high growth companies. I mix in longer form content — think a short blog post that you could read in 5 minutes — with some of my favourite links. Here’s some really popular posts from the past few months:
Stephen
Semgrep
This week, I found a tool that I think is quite revolutionary. That doesn’t happen very often. The last time I remember was dbt, and we all know how much I go on about that thing. So, you, at the back — sit up and take note!
It’s called semgrep. Quoting from the website:
It’s a simple, customizable, and fast static analysis tool for finding bugs
Combines the speed and customizability of grep with the precision of traditional static analysis tools
No painful domain-specific language; Semgrep rules look like the source code you’re targeting
Runs offline on uncompiled code in CI, at pre-commit, or in the editor
Open-source maintained and commercially supported by r2c
As of September 2020, it explicitly supports the following languages:
Go
Java
JavaScript
JSON
Python
Ruby (beta)
JSX (beta)
C (alpha)
OCaml (alpha)
Confused as to what static analysis is? No worry. I’d highly recommend reading my previous issue to get yourself situated before coming back to this issue: The power of static analysis 🤖
So, how does it work?
Although the tool has grep in the title, the similarities end quickly!
grep is a general purpose tool used to find regular expressions in text. semgrep is a tool for running arbitrary rules on abstract syntax trees. This means that it is far more powerful than text based matching, and can understand references, statements, conditionals, and more. It applies rules to source code to check if the desired pattern is found in the source code, highlighting the instances that it finds. When it finds some instances, you can simply log them, or have semgrep exit with a particular status code — useful for implementing as part of continuous integration.
semgrep rules are generally written in the language of the code that you’re targeting, with a small domain specific language to spice things up. This means that there is a very limited domain specific language for you to learn, and you can use all of the knowledge you already have about the programming language. This flattens the learning curve.
But why is this necessary? Can’t we just use grep to find issues in your code? No! To get past a certain level of complexity, you need a tool that actually understands the structure of the programming language, as opposed to pure text. This rich representation means you can do much more powerful selections such as subexpressions, checking when any statements are equivalent to each other, and so on.
How do I use it?
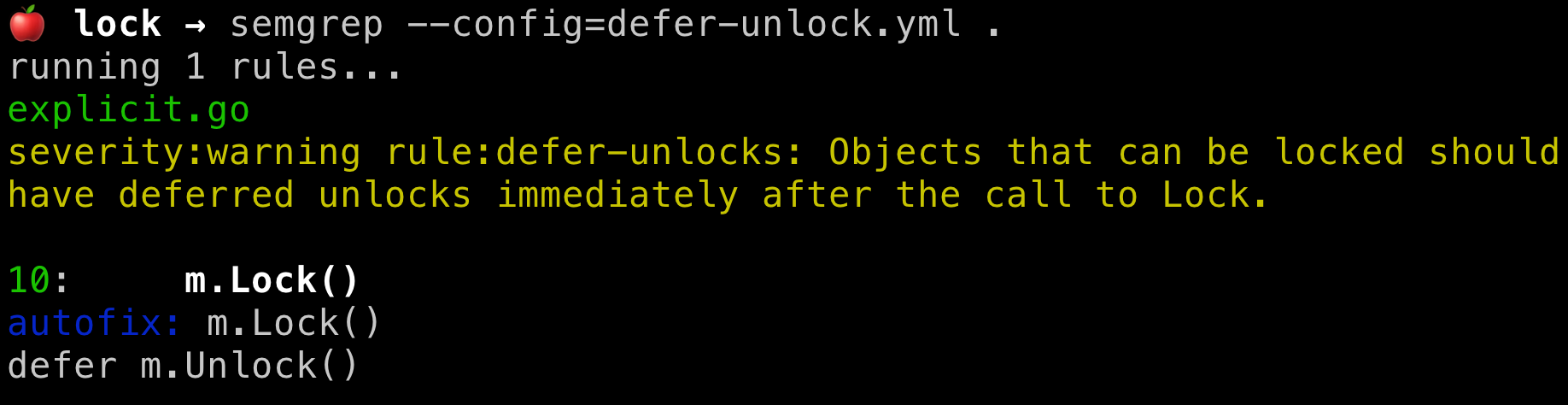
To run semgrep, you use the command line utility, or CLI. Pass in some configuration which contains the rules you want to run, and let it do its thing. In this example, I’m running a toy check that ensures that we defer an Unlock straight after we lock an object — see the rule on GitHub here.
semgrep spots the issue, provides a warning message, and provides an autofix. If you want to apply fixes automatically, just pass the -a flag.
Can I see some more examples?
Sure, let’s go through some toy examples. A warning: examples are not designed to be totally exhaustive or correct in all circumstances. Caveat emptor!
Useless equality checks
A simple one from the semgrep website. This rule checks if you have an expression where the left and right hand side of the expression are the same.
rules:
- id: useless-equality
pattern: |
$X == $X
message: |
The left- and right-hand sides of this expression are identical.
This might seem like an obvious mistake, but it’s surprisingly common! When I scanned the Monzo codebase, I found an example of some test code that was comparing the equality of two structs that suffered from this issue.
Using APIs correctly
Now, let’s get a little more advanced. The below example checks whether you’ve created an errgroup.Group, but forgot to call Wait on it. If you don’t call Wait, you won’t block waiting for functions called in goroutines to finish, nor will you report errors correctly.
rules:
- id: find-unwaited-errgroup
patterns:
- pattern-either:
- pattern: |
# Assign the group and context variable to
# semgrep metavariables. The ellipses mean that
# any arguments can be passed to this function.
$X, $Y := errgroup.WithContext(...)
- pattern: |
$X := errgroup.Group{}
- pattern-not-inside: |
# The ellipses denotes an arbitrary amount of code
# in the current scope. Other functions can be
# be called here.
...
# Ensure Wait is called on $X, which we declared
# as a metavariable earlier on.
$X.Wait()
message: |
You created an errgroup named $X, but never called Wait on it.
How can I use it?
I think there’s three main ways to get a lot of value out of semgrep at an high growth engineering organisation.
It’s a way to query code
Firstly, semgrep is a tool to better understand the structure of your current codebase and the patterns within it. You can write queries that run over your codebase, without having to write custom AST analysis code to do it. For example, you could answer the following questions very easily:
How many microservice handlers are registered that perform no authorization checks?
How many mutexes do we rely on explicitly unlocking, instead of deferring the unlock immediately?
How many database interactions use dynamic string formatting instead of constants?
Although it might seem like a way to answer curiosities, being able to understand the structure of your codebase is very useful in a practical sense. For example:
You can quickly understand the exposure that your codebase has to a particular vulnerability.
You can estimate the size and complexity of an API migration by quickly analysing all of the callers.
These are all extremely relevant questions when your codebase is growing rapidly! 😁
It’s a static analysis tool to spot issues
The natural extension of finding issues in your codebase is adding checks to ensure that those issues can’t return. You can use the rules that you’ve written to highlight unwanted, incorrect or dangerous use of code, and prevent that code from getting checked in to master. This helps keep the bar for correctness and code quality high.
As with any static analysis tool, I’d recommend using it both during development (as part of pre-commit hooks) and in continuous integration (on your CI server). This keeps the loop between writing code and getting feedback nice and tight.
Do you have to generate all of your rules from scratch? Nope. Rule files can be shared amongst the community, so you can benefit from the work of others. There’s a ton on the Semgrep registry for many different languages. There’s also quite a few community contributions scattered around the internet. For example, here’s a great set of rules by Damian Gryski for Go.
A key part to highlight here is the flexibility of semgrep. It’s not just a linting tool that runs a preset list of checks. Because rules are user-specified, it’s a way to enforce norms that specific to you or your company. Perhaps one object must always be initialised in main.go before the other. You might need always need to call a custom authorization function at the start of every handler before you can perform any business logic. Perhaps you don’t permit package level globals at all. You can use the extensibility of Semgrep to continually enforce all of these norms.
It’s a way to automatically fix those issues
Autofixing is an experimental feature within semgrep, allowing you to use simple replacement, or regular expressions, to automatically fix issues raised by semgrep. To do this, provide a fix key in your rule specification. When semgrep is run with the -a flag, it will automatically fix the issue that it spots.
I think there’s some really nice ways to apply this to developer workflows. First, you could run this automatically as part of a pre-commit hook. Issues would automatically be fixed for developers. Second, you could try and use this functionality for mass-refactors or migrations.
As it’s experimental, the power of auto-fixing is currently somewhat limited. But it’s more than good enough to directly swap out functions, or perform some basic refactors. Give it a spin!
Limitations
When trying to express rules with a certain level of complexity, you start to hit some brick walls. Let’s go through some examples.
We allocate a structure in a New() function. As part of this initialisation, a mutex is allocated, and immediately locked. The mutex is then unlocked at some arbitrary point in the future in a totally separate function: e.g. Close(). Right now, I don’t think semgrep can trace calls across all of these functions to ensure that the mutex is eventually unlocked. It’s a lot easier to write checks that look at the current scope, or child scopes.
Another check that I think would be hard to implement in semgrep: ensuring all fields from a particular have been copied into all fields or subfields of another structure. I’m not sure how you’d express a fully generic check over any structure in this way. It’s very possible that this may just be my inexperience with the tool however, so take it with a pinch of salt!
Other tools
It’s also worth taking a look at other tools that do similar things. A referral from a colleague pointed me to CodeQL from GitHub. After taking a quick look at this, it looks very powerful, but quite a bit more complex than semgrep. I’d be tempted to use this if I wanted to build the above checks that I’d find challenging with semgrep. I think I’d find it much harder to explain, however — which would mean adoption within an organisation is likely to be poorer.
There’s also commercial offerings like SonarQube and Codacy, but I have no experience with them, so can’t speak to their quality.
Summary
First and foremost, Semgrep is a powerful and flexible tool for understanding your codebase, and improving the quality and correctness of it. We’re in the process of testing it out at Monzo by adding it on top of our existing static analysis tools. If you like what you’ve seen in this post, it’s probably worth testing out in your organisation too. Let me know how you get on.
Secondly, semgrep feels like a useful primitive to build tools on top of. Being able to understand the syntax tree of multiple different languages seems like a powerful lego block to build other things with. These sorts of tools could be vulnerability scanners, performance optimisers, migration tools, and automatic documentation builders.
Semgrep is a tool well adapted to answering questions and fixing the problems you face in high growth engineering organisations. It’s early days, but I’m excited to see what people can do with it!
Best of the internet 🔗
Every week, I collate some of my favourite links to share. Found something cool, or built something great? Send it to me by replying to this email and I might include it in the next edition. 📧
Network Isolation For 1500 Microservices - Jack Kleeman
I used to work with Jack — he’s great, and so is this video! It details how network isolation was implemented at Monzo. Well worth your time.
r2c meetup: Writing Semgrep rules for security, correctness, performance, and more
Here’s a nice introductory video for how to use semgrep from the commercial supporters of the tool.
Goda: a Go dependency analysis toolkit
Here’s a nice little tool for slicing, dicing and visualising the dependency graph of your Go code.
go-callvis
Wow, I guess I’m really going all out on the Go stuff today. May as well commit. As with Goda for dependencies, this is a nice way to pull apart the call graph — which function calls what — of your program. For large or complex codebases, this can make things a little easier to understand.
That’s all from this week’s High Growth Engineering. If you enjoyed it, I’d really appreciate it if you could do one of the following:
Share it with a friend that would find it useful.
Follow me on Twitter: @sjwhitworth
Subscribe: just hit the button below.
All the best,
Stephen