


Beware the mean 📉
Why averages hide fascinating behaviour

Hello hello, and welcome to another edition of High Growth Engineering 🚀
First, some thanks! I’ve reached 940 subscribers in a little over two and a half months. This number is small for internet scale, but larger than I thought feasible after a couple of months. I was aiming for 1000 subscribers by the end of the year! Thanks for those that read regularly and forward it on to others - I appreciate it.
If you’re a fan of what you’re reading, please click the share button and send it to a friend. ❤️
However, if it’s your first time reading, here’s why I write! The goal of this newsletter is to discuss techniques for building better software and being more effective in high growth companies. I mix in longer form content — think a short blog post that you could read in 5 minutes — with some of my favourite links. I tend to meander between software engineering, product and data science, based on what I’m thinking that week.
Onwards - enjoy!
Stephen
Beware the mean 📉
This was originally posted on my blog, stephen.sh in January 2020.
Those who define key performance indicators, or KPIs, love the mean.
The mean allows you to reduce the chaotic space of human behaviour down to a single number, which you tend to increase or decrease. This compression is tempting, but reductive. The most fascinating — and most important — behaviour lies in the tail of the distribution.
All graphs look the same
I have worked for a few startups at this point. Almost every graph relating to human behaviour that I’ve seen looks like the following:
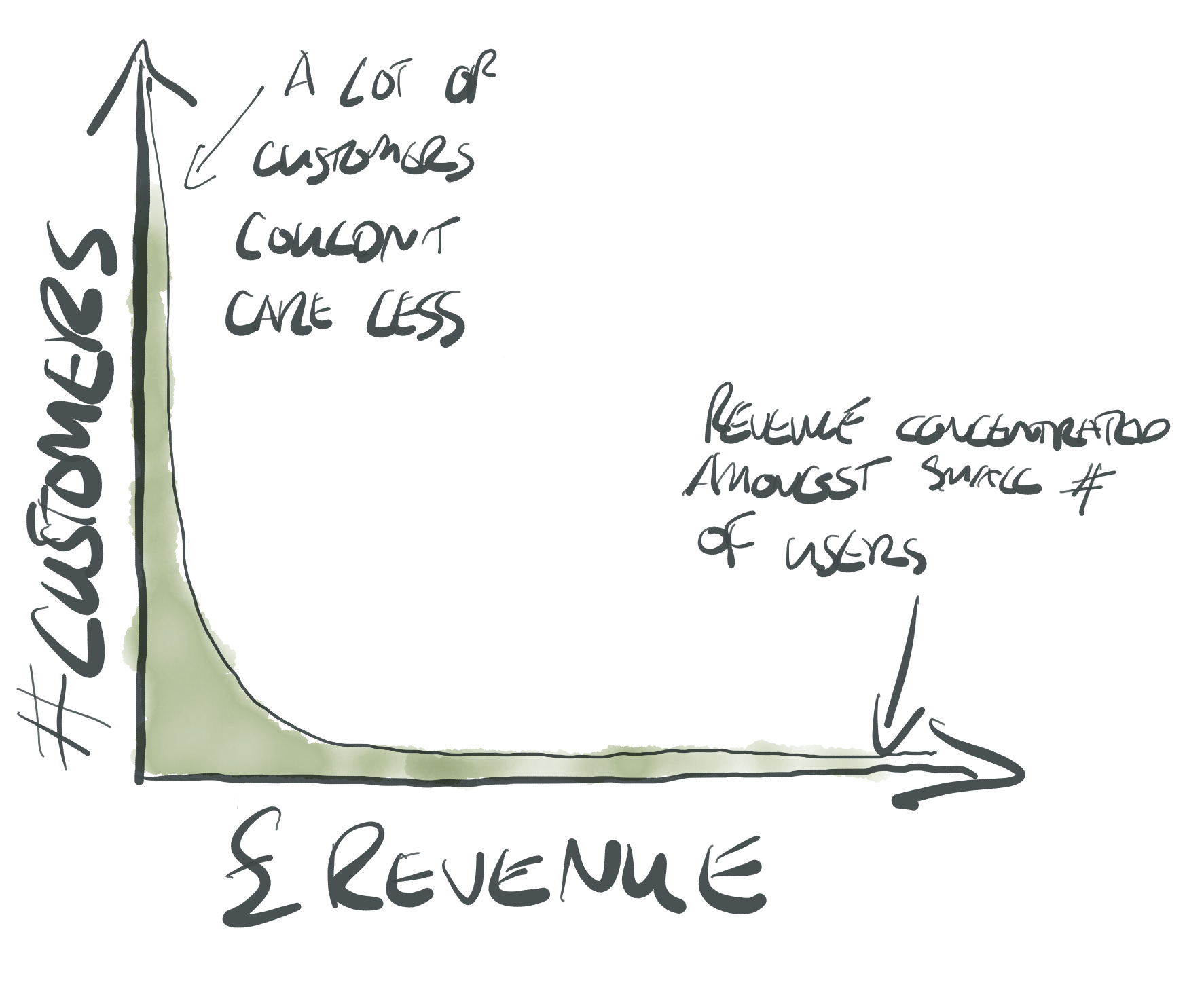
This is a power-law, or the the Pareto principle in action. When you think power-law, think skew: the vast majority of customers contribute negligible revenue, a small proportion of customers contribute almost all the revenue. Switch revenue for engagement, cost, referrals, you name it.
I encourage every person with access to data in a business to study the behaviour of their top 1% of users by some metric (cost, revenue, engagement). What you find will fascinate you!
Upsides and downsides of power laws
Let us view power-laws through the lens of a business thinking about their customers.
The upside of power-laws: if you pick your battles correctly, you can get a lot done with limited effort. Some tweaks will be 100/1000x more impactful than others. The work is in figuring out which tweaks to make.
The downside of power-laws: skewed revenue distributions introduce fragility. Power-laws, by definition, concentrate power in the hands of a few. You are beholden to a small number of over influential customers—if those customers leave, you might be hosed.
If my memory serves me correctly, King (of Candy Crush fame) is a good example of a highly skewed business: the vast majority of their revenue comes from an extremely small percentage of their total user base. 40% of Slack’s revenue comes from less than 1% of the user base. In both these cases, they have managed to mitigate that fragility by scaling the user base by volume. This often isn’t possible for early stage companies: e.g. business-to-business companies that focus on higher-value individual contracts. As a buyer in this situation, this gives you massive leverage.
How to apply this
So Stephen, what do you suggest? If you’ll excuse the pun, means are meaningless in power-laws! I encourage you to consider how you can represent the richness of the underlying distribution when setting KPIs, targets and goals. Use this to start moving the distribution towards the shape you want. For example:
The median customer must be profitable.
The 90th percentile customer must make us £x, the 99th percentile should make us £Y, and the maximum at least £Z.
These targets are far deeper than the mean. The former allows you to ensure that more than half of your customers by number are profitable: this says nothing about how much your worst case customers lose you, and whether you are profitable overall. The latter allows you to shape your revenue to a target distribution, whilst still allowing some skew at the tail for the ‘whales’ of your business.
Should you use these as metrics for your primary goals? Probably not: they’re not particularly catchy, and can be complicated to understand. However, avoid the temptation to squash all behaviour into a single number, and understand the underlying distribution wherever possible.
Best of the internet 🔗
Every week, I collate some of my favourite links to share. Found something cool, or built something great? Send it to me by replying to this email and I might include it in the next edition. 📧
Forecasting with (un)certainty - Taimur Abdaal, Lukas Koebis
This post furthers the argument I make about averages being misleading. It takes a different path, focusing on our need to include uncertainty when we are forecasting. These folks are the founders behind Causal: a product I really like for modelling.
io/fs draft design - Russ Cox
This one is for the Gophers in the crowd. Russ walks us through a proposal to add. The details of the proposal are very interesting, but aren’t why I included the video. What’s great here is the explanation Russ gives: why this particular approach, what tradeoffs are being made, why is it happening now, and so on. Often, these reasonings aren’t included publicly. It was really refreshing to hear Russ speak to them.
Hacking with Andrew and Brad: an HTTP/2 client - Andrew Gerrand, Brad Fitzpatrick
Yes, this week is a little Go heavy. I’m including this because it’s one of my favourite technical videos ever. You get to watch two experienced programmers pair on building something from nothing. I love it. Brad, please do some for Tailscale!
That’s all from this week’s High Growth Engineering. If you enjoyed it, subscribe to get a weekly post in your inbox, free of charge.
Until next time 👋
Stephen