
Writing maintainable code at speed 🏎
How to avoid rapidly creating a big ball of mud

👋 Hello!
For a change, the weather in London was beautiful this week. I think there’s roughly two groups of people in the UK:
Those who welcome the hot weather
Those where any sustained temperature above 15c is a mortal threat
I’d put myself firmly in the first bracket. Long may it last. ☀️
If this is your first time here — hello! I write a weekly newsletter giving guidance and techniques building better software and being more effective in high growth companies. I mix in longer form content — think a short blog post that you could read in 5 minutes — with some of my favourite links that I’ve seen over the week.
Here’s what I’ve covered over the past month:
I have a request of you! This is still a niche newsletter. The most helpful thing you can do is to spread it to others that might enjoy it. Post it internally at work, retweet it, or simple send it to a friend. I’d really appreciate it.
All the best,
Stephen
Writing maintainable code at speed 🏎
I’ve always loved to work really quickly — sometimes to my detriment. I put this down to only working in ‘default dead’ startups, where speed really is one of the only advantages you have.
When shipping is your company’s heartbeat, speed is generally good thing to optimise for. But how do we avoid ending up with a spaghetti mess of a codebase in the meantime?
This edition focuses on techniques you can use to keep your codebase healthy, despite rapid change.
What does maintainable mean?
For every line of code written, a maintenance cost is incurred — the cost of supporting that code into the future.
This cost may be explicit — such as a flaky third party provider that causes on-callers to be paged. Or, implicit — a confusingly written system with few tests. Productivity and happiness drops whenever you interact with this system.
Over time, as traffic scales, or the number of engineers grow, these fixed costs grow larger and larger. It’s reasonable to assume that as a company scales up, they should speed up. For many reasons, this often isn’t the case.
One of those reasons is the difficulty of maintaining and extending their current systems. If we want to go fast, we must minimise this ever-growing, fixed cost of maintenance. Velocity must grow super-linearly over time.

Techniques you can use
So, how do we go quick, but keep things maintainable? Here’s a couple of things that have worked for me in the past.
A note before we start. I steer away from things that may be very hard to change, are specific to one language or tool, or are overly personally biased. For example, I totally believe a statically typed programming language really helps maintainability in rapidly changing codebases. But I think you’re unlikely to re-write your entire codebase in Go — at least, I hope not as a result of a paragraph in this newsletter. Instead, I favour techniques that are applicable to a wide audience.
Boxing up cruft 📦
Speed is a constraint. Constraints may force you to write code that isn’t particularly maintainable, or you’re not particularly proud of. You might cringe when you see it. Don’t worry. It’s called cruft. Cruft is the sort of code that makes you squint your eyes when you look at it, or think “who on earth wrote this?”. Cast those dispersions aside. Used correctly, it’s a great tool.
So, how do we use cruft well? There’s a key concept to understand: the same piece of code can have a different cost of maintenance, depending on how other parts of the system interact with it.
One way to decrease the maintenance cost of cruft is to encapsulate it behind an interface. Let’s go through an example.
Despite recently reaching a market capitalisation of over $1TN, we’re convinced that the era of Amazon is over. We’re going to start our own e-commerce store, and we’d like to launch it in a week. One area that we just don’t have time for in the first instance is building a fancy recommendation system. We’re going to have to do something crufty. What should we do?
In this case, I’d do the simplest thing that you think might work OK, and hide your implementation behind an interface. I’ve never worked for an e-commerce store, but I imagine sorting by the popularity of an item works OK in a pinch. It’s a bit crufty, but we can come back to it later.
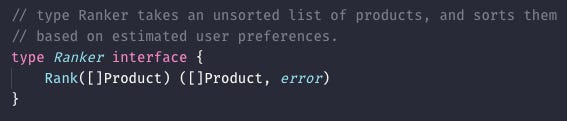
Why does hiding behind an interface matter?
Semantically, you’ve explicitly stated that the consumers of the system should care about the ends, not the means.
Practically, you’ve hidden the mechanics of how your implementation works, so it doesn’t bleed into other systems. This means you can return to your crufty implementation later on, and improve it.
Don’t be ashamed of judiciously-used cruft: but hide it well!
De-couple systems and teams liberally 🍨
‘Coupling’ is the extent to which sub-components of your system depend on each other. If to change a lot of system A, you must also change a lot of system B, A and B are highly coupled. If you can make large changes to system A, but system B needs minimal or no changes, A and B are lowly coupled.
This is a further development of our ‘boxing up’ principle, applied at the scale of systems and teams.
Let’s go through a hypothetical example, with a company called IceCream2U. They deliver authentic Italian gelato to you, wherever you are in the world, for just £5. Unfortunately, some pesky fraudsters have grabbed a bunch of stolen credit cards and are causing massive losses to the company through chargebacks. A new team has been spun up to integrate with a fraud detection service (I know a good one if you’re looking!).
In this example, we have two systems, worked on by two teams:
A newly created fraud detection system, that is being written by the Fraud Detection team. They’re tasked with spotting fraudulent payments and preventing them, whilst providing a good experience to genuine customers. They’ve been told that they should launch as soon as they are ready — every day that they don’t, the business loses more money.
An existing billing system, owned by the Payments team. This service will call out to the fraud detection system to determine whether it should accept the payment. They already have the ability to reject payments.
Even though we have to build at speed, how can we avoid coupling the two teams and systems unnecessarily? Here’s how I’d approach the problem.
Fraud detection team
On the first day, define the types of decisions that you’ll return as part of your interface. Accept and reject seem like sensible places to start: we can make changes later on. Then, create your new ‘fraud detection service’. To start with, it will allow every transaction that it is passed.

Payments team
On the second day, integrate with the new fraud detection service by calling it. For safety purposes, ignore any decision that isn’t accepting the payment, and alert the Fraud Detection team when this is the case.
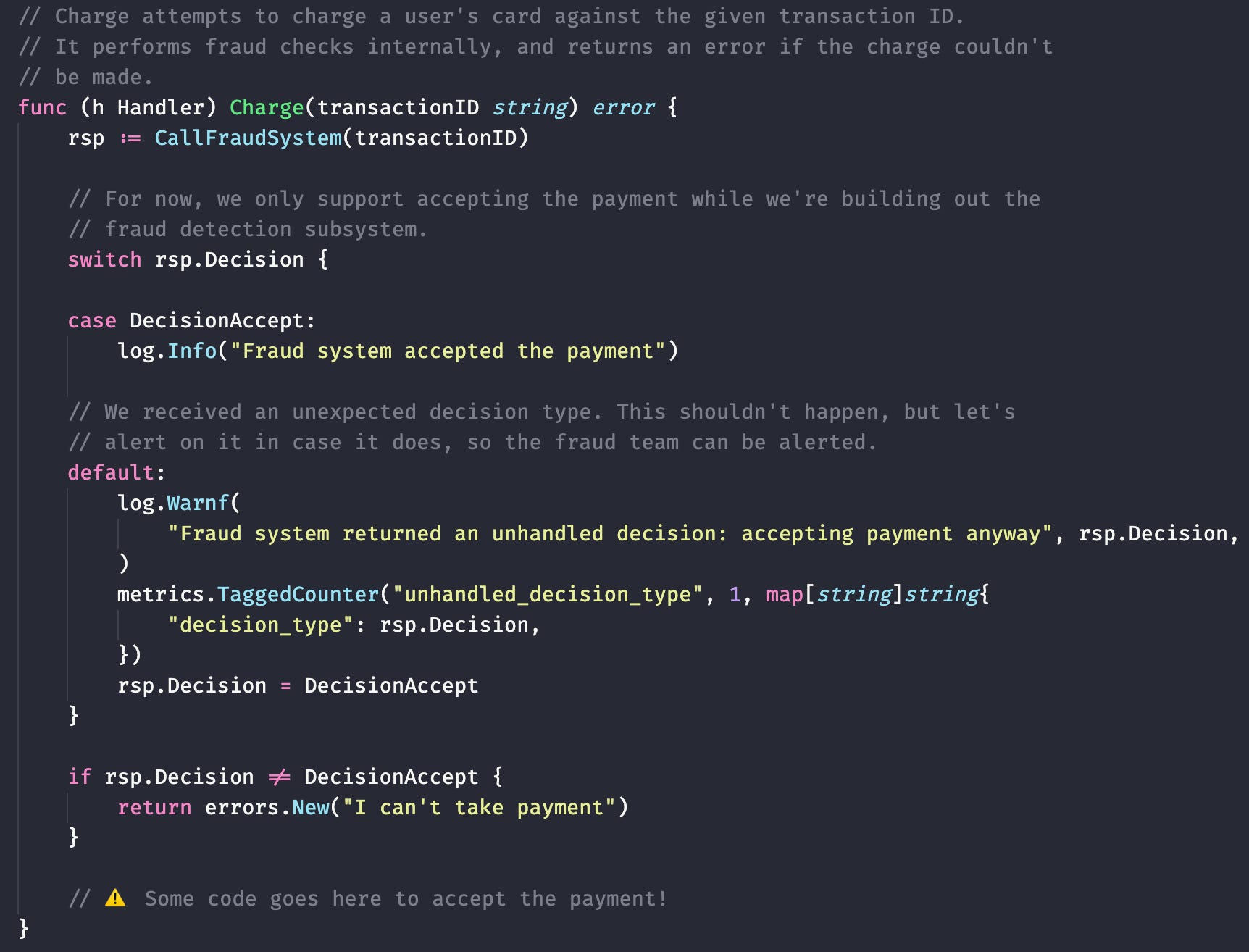
With trivial amounts of work, we’ve now got the foundations in place. The Fraud Detection team can get to work on building a great system to predict fraud with the data they’re being passed, knowing that there’s no possible way that their system can reject any live payments.
Let’s fast-forward a little. The Fraud Detection team now has a promising model for predicting fraud. They’re ready to launch an experiment where they’ll send a percentage of payments to the new system and start rejecting payments. They send a pull request to the Payments team, removing the ‘safety code’ that was added — they now want the ability to reject payments.

They roll out their change, but with the experiment switched off. The system is still accepting all payments.

Later on in the week, they launch their experiment. They’re now stopping fraud. 🎉
This example highlights a few important themes:
Going quick doesn’t always mean trading off maintainability. Nothing in this example is crufty.
Synchronisation between teams can kill speed. If you must synchronise, it’s best to synchronise against interfaces, early on. This is a ‘formal’ way of specifying how your systems will interact with each other. Once you’ve put the foundations in place, teams can work independently of each other against these interfaces.
Smaller changes are generally safer changes. At each stage, we didn’t change much, but ensured that it was safe.
Static analysis
I believe static analysis is the single most underrated tool for maintaining quality at speed:
It is an automated enforcer of norms within organisations.
It relieves engineers from the mental burden of spotting and pointing things out at code review.
It tightens the loop between writing code, and seeing whether it’s acceptable to the organisation.
It can explicitly target maintainability, not just correctness, by analysing the way the code was written. This is challenging to do in any other automated way.
I’m going to write a whole issue about it soon. 💓
Fast and reliable unit tests
First, a carefully maintained test suite speeds you up over time, and provide guardrails against future regressions.
Second, as touched on above, they’re a great way of reducing the time in a feedback loop as a developer from typing to understanding whether your code is acceptable or correct.
Best of the internet 🔗
Every week, I collate some of my favourite links to share. Found something cool, or built something great? Send it to me by replying to this email and I might include it in the next edition. 📧
Is High Quality Software Worth the Cost? - Martin Fowler
If you’re interested in what I discussed above, this is a must read. Martin argues that to consistently achieve speed over time, you need to maintain high internal quality: “high internal quality reduces the cost of future features”.
Load bearing quirks - @mcclure111
I thought this was a really well put thought. In code, it’s difficult to communicate which quirks are intentional, and which aren’t. This is why I get frustrated with the anti-comments-in-code crowd.
Causal - Taimur Abdaal, Lukas Koebis
Causal is a beautiful tool for playing with numbers. I found this on Saturday, and spent the afternoon with it. It’s really nice to be able to explicitly input probability distributions within Causal, and have the tool perform simulations for you. I think it’s going to be big.
That’s all from this week’s High Growth Engineering. If you enjoyed it, I’d really appreciate it if you could do one of the following:
Share it with a friend that would find it useful.
Follow me on Twitter: @sjwhitworth
Subscribe: just hit the button below.
All the best,
Stephen